Data lake with Pyspark through Dataproc GCP using Airflow
In my previous post, I published an article about how to automate your data warehouse on GCP using airflow.
Automate Your Data Warehouse with Airflow on GCP | by Ilham Maulana Putra | Jan, 2022 | Medium
This time, I will share my learning journey on becoming a data engineer. In this post, I will try my best to tell the steps on how to build a data lake with Pyspark through dataproc GCP using airflow.
What is Data Lake?
A data lake is a storage repository that holds a vast amount of raw data in its native format until it is needed for analytics applications. (Craig Stedman, Large)
Why do the companies or organizations need a data lake?
Companies or organizations use data lake as a key data architecture component. Commonly, they use a data lake as a platform for data science or big data analytics project which require a large volume of data.
What is Pyspark?
PySpark is an interface for Apache Spark in Python. It does not only allow you to write Spark applications using Python APIs but also provides the PySpark shell for interactively analyzing your data in a distributed environment. PySpark supports most of Spark’s features such as Spark SQL, DataFrame, Streaming, MLlib (Machine Learning) and Spark Core. (Official Documentation)

Running PySpark on DataProc GCP
Google Cloud Dataproc is a fully managed and highly scalable service for running Apache Hadoop, Spark, Hive or 30+ open source tools and frameworks. Dataproc automation helps the user create clusters quickly, manage them easily, and save money by turning clusters off when you don’t need them. With less time and money spent on administration, you can focus on your jobs and your data. You can read more about DataProc here.

Data Pipeline

In this story, we will look into executing a simple PySpark Job on the Dataproc cluster using Airflow.
Airflow DAG needs to be executed and would comprise of below steps:
- Create a Cluster with the required configuration and machine types.
- Execute the PySpark (This could be 1 job step or a series of steps)
- Delete the Cluster.
For this example, We are going to build an ETL pipeline that extracts datasets from data lake (GCS), processes the data with Pyspark which will be run on a dataproc cluster, and load the data back into GCS as a set of dimensional tables in parquet format.
The dataset we use is an example dataset containing song data and log data. We are going to transform the dataset into four dimensional tables and one fact table.

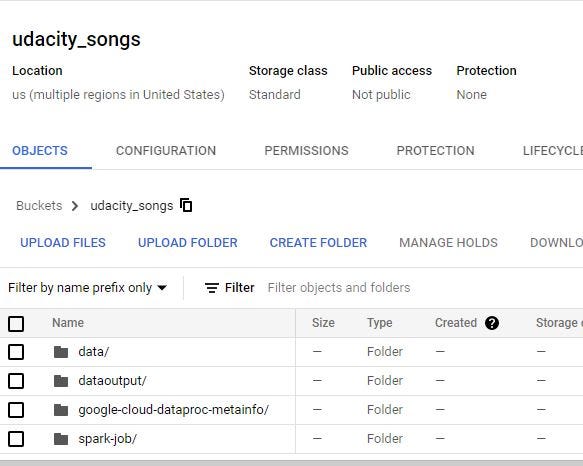
Let’s start with uploading our datasets and Pyspark job into our Google Cloud Storage bucket. Check my Github repo for the full Airflow DAG, Pyspark script, and the dataset.
Before Uploading the Pyspark Job and the dataset, we will make three folders in GCS as it shown below.


Pyspark Script
This Pyspark script will extract our data in the GCS bucket data/ folder, transform and process them, and load it back into the GCS bucket data output/ folder.
Automate Pyspark job and running it with Dataproc Cluster using Airflow
We will be using dataproc google cloud operator to create dataproc cluster, run a pyspark job, and delete dataproc cluster.

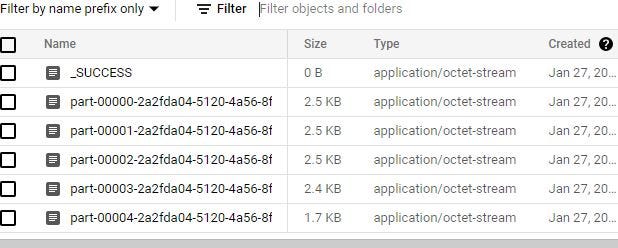
After all the tasks are executed. We can check the output data in our GCS bucket data output/ folder and the output data will created as parquet files.

So, That’s it. We can automate our Pyspark job on dataproc cluster GCP using Airflow as an Orchestration tool. We can just trigger our dag to start the automation and track the progress of our tasks in Airflow UI.
